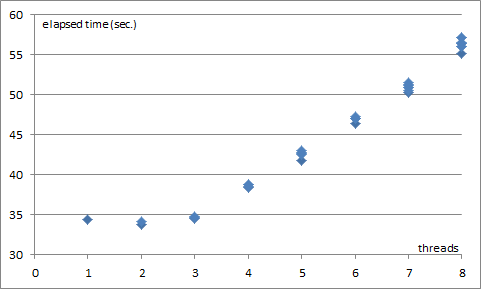
前回の並列実行の検証では、3スレッドまでは高い性能向上を示した後、伸び率が低下することが確認されました。
今回は、この時のOS統計を確認します。
【CPU】
CPU使用率の推移は以下の通りです。
※なお、検証環境の物理コア数は4です。
 |
| Figure 3: CPU usage |
設定したスレッド数以上のコアが使用されていることが確認できます。これはJVM自身の挙動に関わるオーバーヘッドであり、これらを含めたスレッド数が物理コア数を超えたことで4スレッド時点で性能の伸び率が鈍化し始めたと想定されます。
※本記事ではこれ以上の調査は行いません。
過去にCOM経由でエクセルを操作した際の値と比較すると、CPU使用率が非常に低く抑えられています。性能の伸び率の高さは、このCPU使用率の余裕から生まれていると考えられます。
プロセッサ・キュー(Processor Queue Length)の値は6スレッドから目立ち始め、7スレッド以降は過負荷であることを示しています。
 |
| Figure 4: Processor Queue Length |
参考まで、コンテキスト・スイッチ(Context Switches/sec)の発生も確認します。COM経由でExcelを操作した際の値と比較すると、10分の1以下で推移しています。
 |
| Figure 5: Context Switches / sec |
【メモリ】
スレッド数の増加に伴って開きメモリが減少しますが、5GB以上の余裕があります。
グラフは割愛しますが、ページングも発生しておらず、問題は見られません。
 |
| Figure 6: Available Memory (MB) |
【ディスク】
ディスクへの負荷はそれほど高くありません。グラフは割愛しますが、キューの待機も発生していません。
 |
| Figure 7: Disk usage |
【GC】
今回はヒープを十分に確保(1GB)したため、Full GCは発生していません。参考まで、以下にJVMの推移を示します。
 |
| Figure 8: GC |
※NEWについては改善の可能性もありますが、今回の検証ではこれ以上のチューニングは行わないこととします。
【結果】
以前の検証でエクセルによる帳票出力(COM経由での操作)を行ったときと同様、CPUの処理容量に依存しやすい傾向が確認されました。
※参照:「リンク」
COM経由でエクセルを操作する場合と比較すると、単位時間当たりの出力性能はApache POIが大幅に上回っています。
また、Apache POIを使用する場合はサーバ側のOSを選ばない点、およびサーバ側にエクセルのライセンスが不要である点も優位であるといえます。
しかしながら、Apache POI(またはその他のライブラリ)を使用する際には機能制限に留意する必要があります。現行バージョンの3.7ではXSLX形式の条件付書式に対応していない(次期3.8で対応予定)等、ユーザ要件を満たせない場合があります。エクセルのもつ機能・表現力を十分に発揮させたい場合には、これらの機能制限が不利となります。
帳票要件の複雑さと処理性能や実装環境を考慮し、Excelによる実装とApache POI等の外部ライブラリでの実装を使い分けることをお勧めします。
管理面からは「実装方式を一本化する」という方針が魅力的に見えることがありますが、実際には機能制限の回避や性能問題の解消などに不要な出費を強いる原因となりがちです。技術者の確保も容易な分野ですので、相当の理由がない限り、一本化は避けることをお勧めします。
[Summary]
OS statistics shows that Apache POI file processing is CPU bound.Please see Figure 3 to 7.
For your reference, Figure 8 shows JVM GC statistics.
The advantages of Apache POI: The performance Apache POI manipulation is much faster than the performance of COM-Excel manipulation. In addition, you do not need the Excel licence on the server side.
The disadvantage of Apache POI: Apache POI does not support all the functions that Excel provides.